From the creator of Hack, the language behind Facebook’s business logic, comes a closed-loop coding agent that turns one prompt into running software.
PARIS, FRANCE — June 1, 2026 — SkipLabs today launched Skipper, a closed-loop coding agent that takes a single prompt and returns a running, validated service. Skipper was built by Julien Verlaguet, creator of Facebook's Hack programming language, alongside a team of engineers drawn from Facebook, Microsoft, Microsoft Research, Meta and the broader systems community. It serves as the architectural layer sitting between AI models and shipped software.
Skipper is designed specifically for technical builders: product managers running their own AI workflows, engineering teams shipping production services, and developers who demand architectural discipline without architectural overhead.
The Missing Link in AI Coding
Skipper arrives at a critical inflection point. While AI coding tools have made the first draft of a service nearly free, what remains is the gap between almost running and actually running in production. This is an architecture problem—one that doesn't disappear just because a language model gets smarter.
"Building correct software has always been an architecture problem disguised as a coding problem," said Julien Verlaguet, Founder and CEO of SkipLabs. "AI did not change that; it just made the problem more urgent."
Skipper sits beneath the foundation models. Rather than competing with Claude, GPT, or Gemini, it acts as the substrate that turns their output into finished software rather than a draft awaiting review. When a builder describes the service they want, Skipper handles the entire pipeline autonomously: decomposing the work into manageable pieces, routing each piece to the specific AI model best suited for that task, generating and validating the code, and returning a reliable, running service. No developer review, no oversight cycles, no back-and-forth.
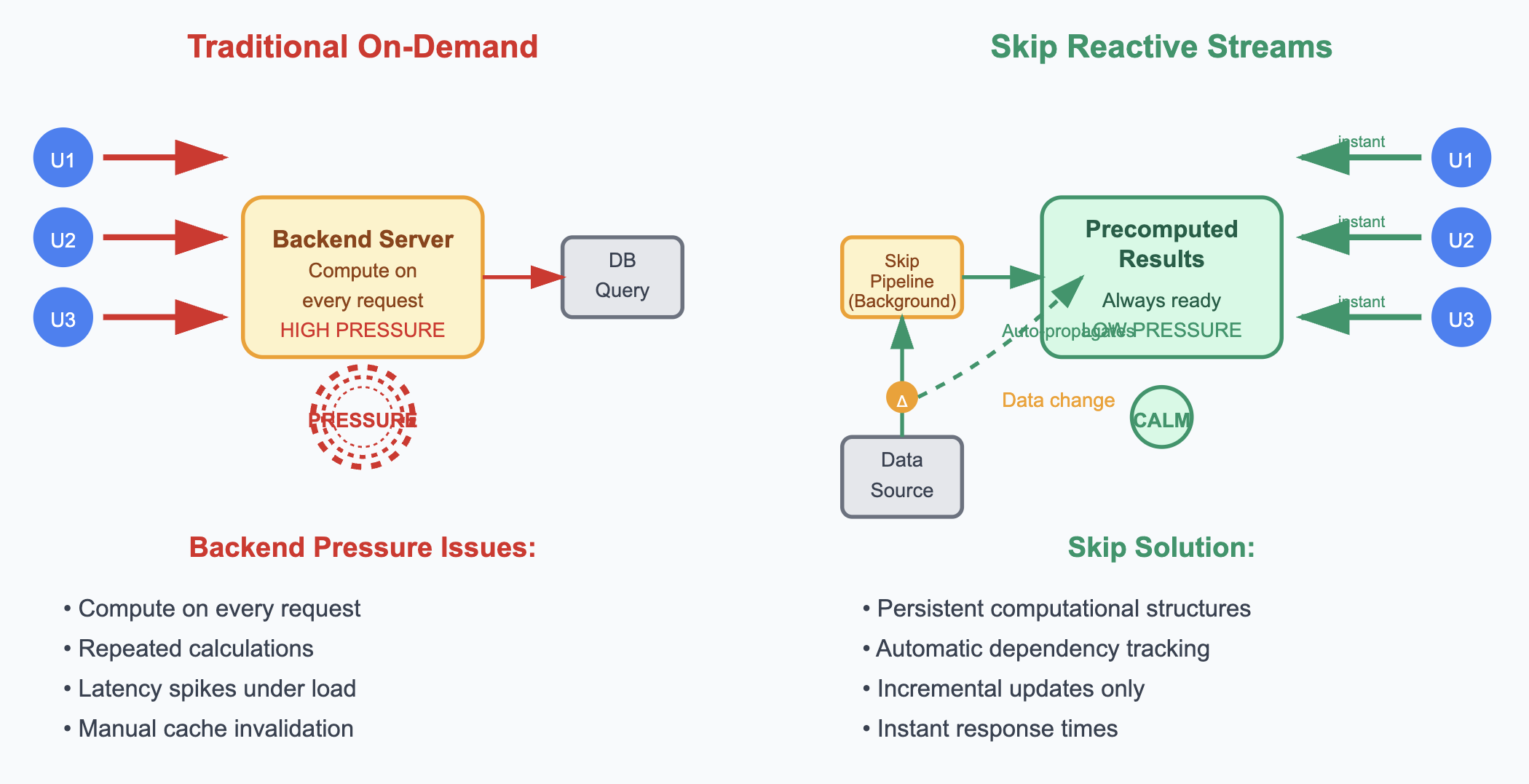
Fixing State and Concurrency
State management and concurrency are the hardest parts of writing correct software, and the exact areas where AI most often produces broken code.
Skipper solves this via its reactive runtime—drawn from the open-source Skip framework Verlaguet built at Facebook in 2017. Because the runtime automatically handles state management and concurrency, the AI model never has to reason about cause and effect across a sprawling state graph. By shrinking the surface area where AI can make mistakes, Skipper ensures more of what it produces actually works.
"Closed loop is not a feature," Verlaguet added. "It is a different theory of what an AI coding tool is supposed to do. The current generation makes the developer faster. The next generation makes the developer's involvement optional. Describe what you want and Skipper builds it."
What Ships Today
Launching today, Skipper delivers the core closed-loop experience: a single prompt becomes a running service. A model-agnostic harness routes each task to the AI model best suited for it, with no lock-in to any single foundation model. And Skipper-built services integrate with the outside world from day one — calling external APIs, fetching live data, and posting to other systems to ensure the software fits into a real stack, not just a sandbox.
The Product Roadmap
In the weeks following launch, SkipLabs will roll out SKJS, a sound, TypeScript-compatible type system that lets Skipper understand how changes to one part of the code affect the rest. Next comes in-place incremental updates, allowing builders to change a specification and have Skipper modify the running service without a full rebuild. By late 2026, SkipLabs will deliver precise, zero-pollution awareness of the full codebase at any scale.
Who Skipper is For
Skipper is built for those who experience the frustration of watching an AI generate a near-working idea, yet possess the technical knowledge to see exactly why the last 10% breaks. It is designed for technical product managers wiring AI into production tools via real API integrations rather than sandboxed demos. It also serves engineering teams shipping production backend services who want architectural discipline without the per-line review cycle, and software development firms building AI-driven systems for clients whose code absolutely must ship.
A Decade Making Code Provably Correct
The architecture beneath Skipper predates the current AI coding wave and is backed by over a decade of infrastructure-first philosophy. Verlaguet created Hack, the gradually typed programming language that powers Facebook's business logic and over 100 million lines of production code. Amplify Partners, which led SkipLabs' $8 million seed round, noted in its investment memo that Verlaguet is "one of the top two to three programming language designers in the world." His work on programming language design has also been publicly endorsed by Turing Award winner and former Meta Chief AI Scientist Yann LeCun.
Skipper is available today at skipperai.dev.
About SkipLabs
SkipLabs builds the infrastructure layer that makes AI-generated code work in production. Founded in 2022 by Julien Verlaguet, creator of Facebook's Hack programming language, the company develops tools that close the loop between intent and running software for technical product managers, engineering teams, and the firms that build production systems on top of AI. SkipLabs is backed by Amplify Partners, with angel investors including Yann LeCun and Spencer Kimball, co-founder and CEO of Cockroach Labs. For more information, visit skiplabs.io.